Sudadu
Table of Contents
Team Information #
- Sunkyu Kim(BE) : https://seonkyukim.github.io/about/
- Jaehong Jung(FE, ML serving) : https://jaehong21.com/
- Junmyeong Lee(ML) : https://slime0519.github.io/
- Galyoon Jae(BE, ML serving) : https://yunjegal.notion.site/Yun-Jegal-a1aab6ba45574b2e8f058b5f382bfabb
About our service #
Our service has been developed to assist high school students in Korea with their mathematics learning. High school mathematics education in Korea covers a wide range of topics including algebra, geometry, and more, and it involves various types of problems. As a result, it is not easy for students to make fast learning progress. Therefore, our team has developed a service that, when students capture a problem they are unfamiliar with, recommends similar problems to help them quickly improve their areas of weakness.
System Design #
To facilitate the recommendation of similar problems, our team utilized an embedding-based similarity search approach. The embedding-based method make system to robust in handling unseen data and require tiny computation cost in inference time. Additionally, if we need scalability and speed optimization, we can attach vector search frameworks like faiss, on the vector index.
This system runs on CPU inference only, with no GPU instances. So, we were able to build a low-cost system using only AWS lambda instances for computation.

The sequence of events above happens in real time
- A user takes a picture of a math problem and passes it to the backend API.
- The backend API calls the MathPix API to convert the math problem image into a Latex String.
- The backend API gets the embedding from the converted Latex String by making an Inference API request.
- Select the 3 most similar math problems from the existing problem set stored in S3 using the Embedding similarity and respond to the user.
1. FE #
- Flutter (Dart Language) App Framework for both Android & iOS
2. BE #
- Model inference API
- Packaging ML model via BentoML
- Serving via AWS Lambda + API Gateway
- Python + FastAPI
- Backend API
- Serving via AWS Lambda + API Gateway
- Python + FastAPI
- Data Lake & DB
- AWS S3
3. Data Pipeline #
Considering the time limit and data quality, we have decided to extract math problems from the EBS-deployed “수능특강” workbook. Since the workbook is in PDF format and not a scanned copy, it doesn’t contain various image noise, and we can quickly collect data using metadata. Therefore, we have chosen the “수능특강” as our data source.
Process of collecting answer-problem pairs:
- Apply a pre-trained YOLO v5 model to generate pseudo-labeled bounding boxes for the answer and question sheets.
- Conduct a manual chec to identify and correct any inaccurately detected bounding boxes.
- Utilize the text metadata and bounding boxes extracted from the answer sheet PDF to assign labels to each bounding box, indicating its corresponding problem.
- Employ the “LabelImg” tool to verify the accuracy of the assigned problem labels on the answer sheet.
- Align the problem set derived from the answer sheet with the bounding boxes of the question sheet.
- Verify the correctness of the assigned problem labels on the question sheet using the “LabelImg” tool.
- Extract the problems from the obtained bounding boxes and convert them into LaTeX strings by leveraging the Mathpix API.
The initial YOLO v5 model was trained using approximately 200 hand-labeled data samples. Through the semi-automated data collection pipeline, the data collection time for one year’s workbook has been reduced from 150 minutes to 15 minutes, resulting in an efficiency improvement of about 10 times.
ML Component #
In our product, the model plays a role in converting problems into vector embeddings. To embed sentences converted into LaTeX strings, we fine-tuned the model from the sRoBERTa model, which was pretrained on the KLUE NLI/STS dataset. This fine-tuned model allows us to convert problems into 768-dimensional vectors for embedding purposes.
Experiment 1. Score-based Regression #
As a similar approach to the STS (Semantic Textual Similarity) task. We trained the model by assigning scores to random sampled pairs of sentence embeddings, aiming to make the cosine similarity between the embedding vectors similar. Specifically, when the difficulty level and sub-topic of the problems were the same, we set the scoring mechanism to assign higher similarity scores. This approach ensures that problems with the same difficulty level and sub-topic receive a higher similarity rating.
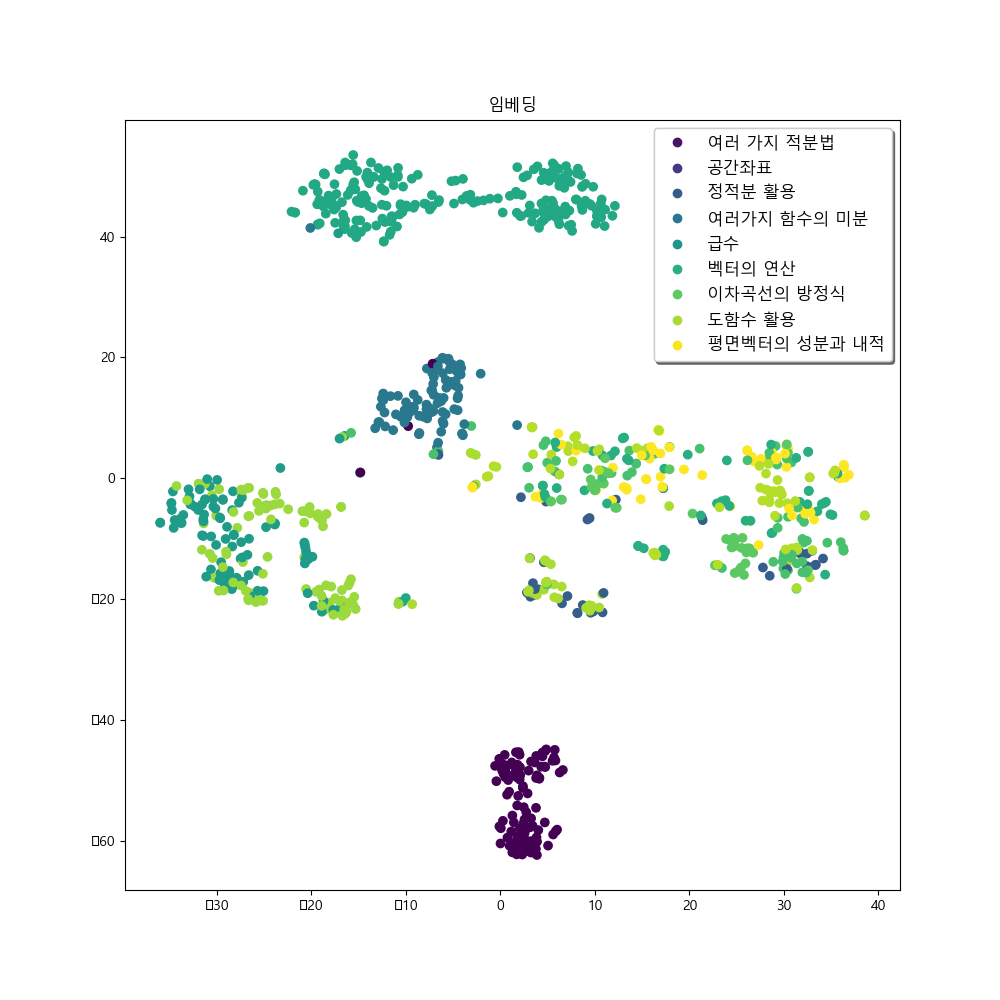
The fine-tuned model trained with score-based loss, demonstrated significantly better results than the pretrained model when it came to geometry problem dataset. It can also be observed in the t-SNE embedding results below:

Experiment 2. Contrastive Loss #
The score-based loss alone was unable to capture semantic information for larger problem domains such as calculus and geometry. Instead, it exhibited a tendency to encode superficial information about the sentence structure and the words used. To overcome this limitation, we introduced contrastive loss for chapters:

By incorporating contrastive loss, we were able to provide direct negative feedback, leading to better recommendation performance compared to using only the score-based loss. This improvement is also evident in the visualization.
The figure below represents the results of training with the addition of contrastive loss. It can be observed that the model’s embeddings show clearer separation among chapters related to calculus and geometry compared to the embeddings of the previous model. This distinction is particularly noticeable for the problem set-“여러 가지 함수의 미분.” However, there is a tendency for reduced cohesion in some clusters within the geometry problem data, compared to the previous approach. This is an area for further improvement in future iterations.
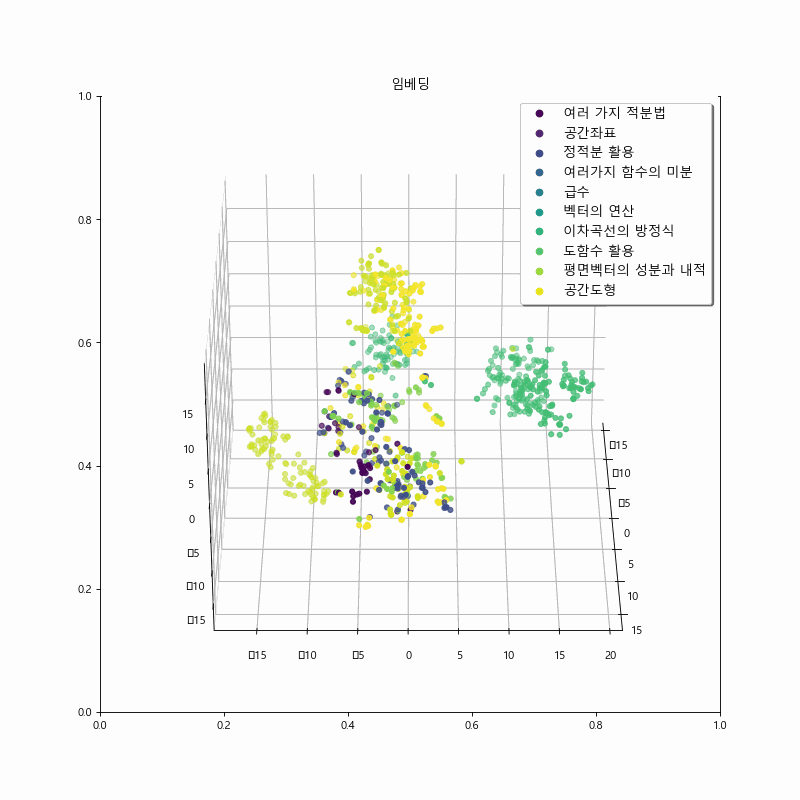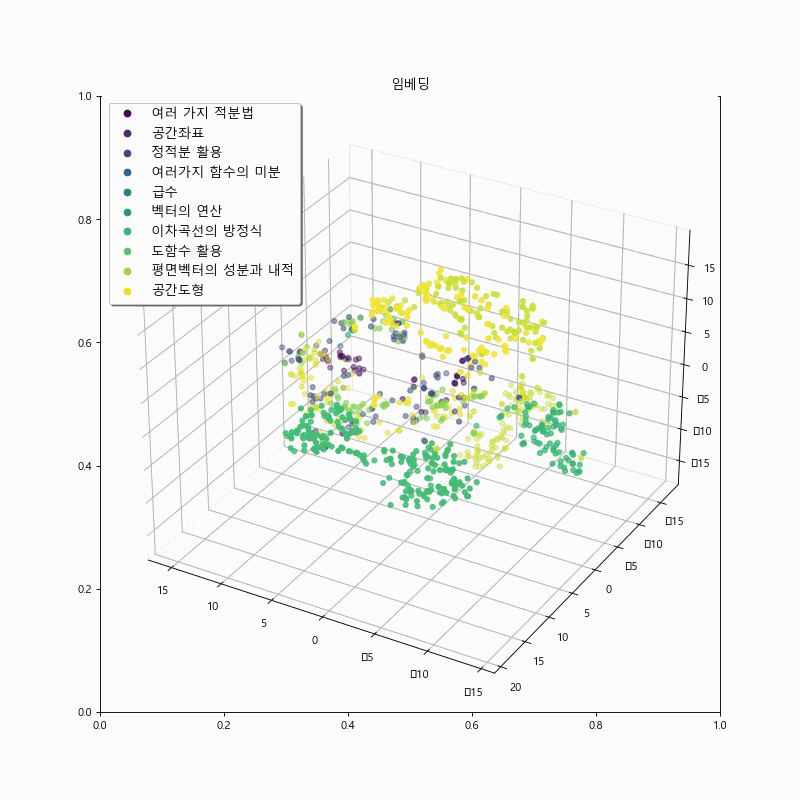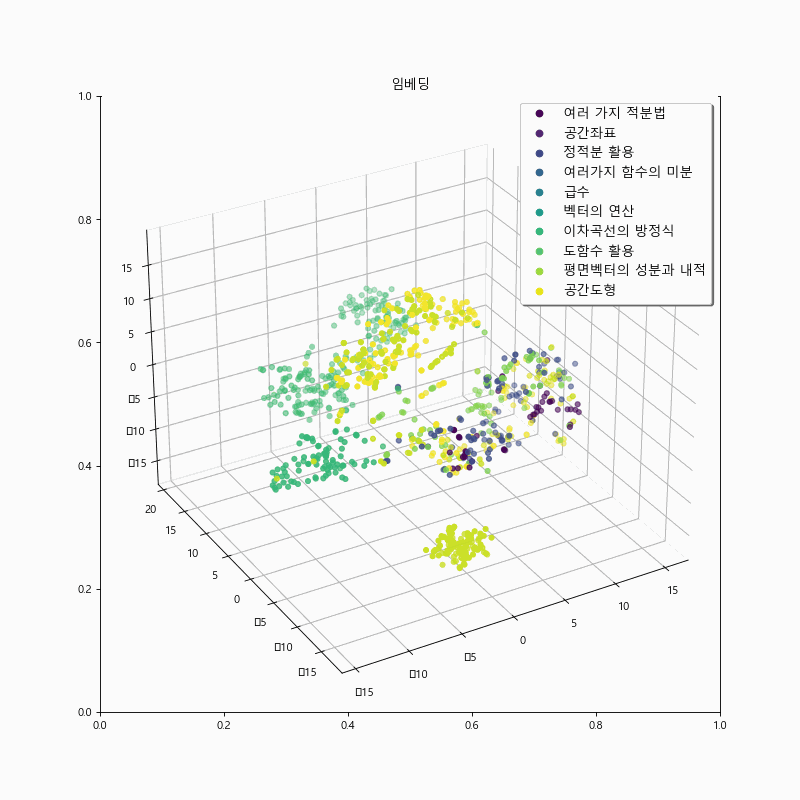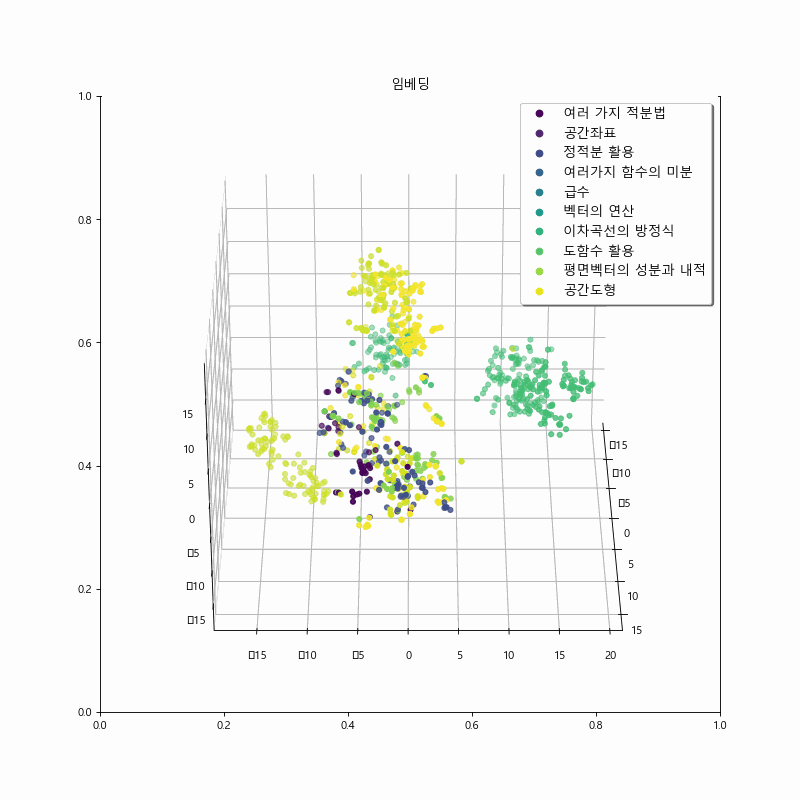
Experiment 3. Unit and Level classification via OpenAI #
Our team used the OpenAI API to fine-tune the models for classifying unit and level of problem. It has to be considered the design for prompt and a corresponding class. It is added the separator to the end of the prompt to indicate where the prompt ends and completion begins, and we use the \\n\\n###\\n\\n separator at the end of a prompt, and add the same separator for inference. Furthermore, since the token length for classes must be 1, the collected labels obtained above could not be directly used. Instead, each label was assigned to an integer with a token length of 1 and used for training. In order to measure accuracy, it was necessary to divide the training data and validation data for fine-tuning. However, due to the limited number of collected data, approximately 500 samples for each subject, a separate validation set was not created. Due to the significantly low cost and time of training, the model was refined by directly examining the inference results for any inconsistencies after training. In case of identified awkwardness, additional data was collected and retrained the model.
System Evaluation #
Total response time #
The average backend API has a response time of 3 to 4 seconds. The backend server sends an API request to the inference server, which makes three API calls: embedding, level, and unit. This process had a huge impact on response time, and I think the user experience would have been better if we had designed it to receive all responses at once.
Response Time of Model API #
Performance test was evaluated with 1, 10, and 20 concurrent users.

The model infrastructure is tested with 1, 10, and 20 users. It is such that a single user can send 3.3 requests per second(RPS). The converged RPS for 1, 10, and 20 users is 3.3, 39, and 77, respectively, showing a proportional increase in the number of users, and no failure responses were found for all cases. Regardless of the number of users, the response time was mostly constant at 0.25 seconds at the 50 percentile and 0.34 seconds at the 95 percentile. However, there are occasional cases where the response time is as high as 6s, but we decided that this was not a critical issue in the early days of the service and did not take any further action due to its low frequency.
Actions to avoid AWS Lambda cold start #
It is noticed that the 95 percentile time was over 30 seconds as shown in the test results above. It has a negative impact on the service experience. Due to the nature of Lambda, the instance is initialized after about 10 minutes of running, and the next call sets up a new environment for the function to run in. At this point, the model image size was large at 2.4GB, so it was taking a long time to load from Amazon ECR and run, which is usually called a cold start issue.
The first thing we tried was configuring provisioned concurrency in AWS Lambda. Provisioned concurrency is the number of pre-initialized execution environments to Lambda function and these execution environments are prepared to respond immediately to incoming function requests. The downside is that it’s expensive, so we consider the another way. The second method we tried was to call Lambda function directly to keep it running. Cronjob is created using AWS EventBridge to trigger function every minute to keep it warm, and as a result, 50 percentile of response time is around 0.25 seconds and the 95 percentile of response time down to 3 seconds.
Application Demonstration #
Our frontend application was designed and built using the Flutter framework, chosen for its wide range of benefits. First and foremost, we wanted to offer our service as a mobile application rather than a web-based solution, given the nature of our service. The app requires students to capture images of their math problems, making a mobile interface the ideal choice for ease of use and practicality.
Secondly, we chose Flutter to increase the accessibility of our service. Flutter is a cross-platform framework, allowing us to develop our application for both iOS and Android platforms simultaneously. This broad compatibility makes our service accessible to a wide range of students, regardless of the type of smartphone they use.
Compared to other hybrid mobile app development frameworks like React Native, Flutter stood out for its better support for camera plugin, which is a crucial feature for our app given its dependence on capturing images of math problems.
The usage of our service via the smartphone application is straightforward. A student simply takes a picture of a math problem, and then hits the check button. The application then uses the image to identify the problem, find similar problems within the same topic or chapter, and provide these similar problems to the student. This way, students can effectively learn by solving problems similar to the ones they are struggling with, enhancing their understanding and mastery of the topics.
As of now, the application is in its demo stage and mainly serves the function of problem identification and recommendation. However, future improvements will include more personalized features and bulk recommendations of similar problems, elevating the learning experience for our users. The potential for expansion and further refinement of our application is significant, and we look forward to continuing to improve our service.
Reflection #
In order to build the high school math problem recommendation service, we performed the following tasks:
- Constructed an efficient pipeline for collecting Korean math problems
- Trained a Korean math problem embedding model using ko-SRoBERTa:
- Built a recommendation system based on vector search using AWS Services without expensive GPU instance
- Developed a smartphone app front-end using Flutter for students’ easy access
Through these tasks, we aimed to create a comprehensive and efficient service that helps high school students with their math learning journey.
Future works #
Based on multiple project mid-reviews, demo days, and the feedback we have received through our experience, we have considered the following tasks that will be necessary in the future:
Business Perspective #
- How to increase user engagement?
One feedback we received was that while our service is technically sound, it lacks in terms of user engagement. This was evident from the overwhelming number of low-value coins received during the demo day compared to other teams.
Therefore, in the future, we need to consider what features can truly assist high school students in their learning journey in conjunction with problem recommendations. Additionally, we should explore potential business models for commercializing the service.
- What is good recommandation?
A recurring question that we received during multiple review sessions was, “What makes a good problem recommendation?” Since preferences for good recommendations can vary depending on individuals, continuous improvement of our recommendation policy is crucial. To address this, we have implemented a user feedback button on the problem recommendation page. This allows users to provide feedback on the recommendations they receive, which will help us refine and enhance the recommendation algorithm.
Technical Perspective #
- Latency of recommendation
Currently, it takes around 3-4 seconds to fetch recommended problems in the smartphone application. There are two main reasons for this: 1) inefficient internal API call procedures, and 2) large model parameter sizes. To address this, we can restructure the inefficient call procedures to be more asynchronous and explore various lightweight techniques to reduce latency, significantly improving the user experience.
- Scalable Vector Search
The current system retrieves the top-3 problems by calculating the cosine similarity between the embedding vector of the user’s input problem and all the embedding vectors in the database. However, this k-NN vector search implementation can be computationally inefficient. By utilizing libraries such as faiss or annoy that provide approximate nearest neighbor (ANN) search, the system can maintain nearly the same response speed even when the problem dataset is scaled to a large extent.
- Unit/Level classification model
Due to time constraints, we are currently using a fine-tuned ChatGPT API for predicting the subunit/difficulty level of problems. However, the accuracy is around 80% and requires improvement. Internal experiments have shown that constructing a model based on problem embeddings can lead to better prediction models. The (x_cls_acc) plot in the experiment logs demonstrates the accuracy when training a subunit classification model after the problem embedding model. As the accuracy significantly improves from the early stages of training, there is potential for further development in this area.
Broader Impacts #
1. Copyright Issues #
In our project, we collect and provide mathematical problems, which requires attention to copyright issues. Some malicious users may collect the recommended problems and distribute our problems in a way that violates copyright, by using our content. Therefore, it is important to provide users with sufficient guidance on how to correctly use our service.
First and foremost, we need to be aware of the sources and copyrights of the problems. If necessary, we should seek agreements or permissions regarding copyright and ensure that proper attribution is given to prevent copyright infringement. By doing so, our project can appropriately address copyright issues and gain respect in society.
2. User Data Collection #
In our project, we have determined a policy to collect problems captured by users and add them to the database. This can raise concerns related to personal data protection. We must respect users’ personal information and comply with data protection laws and relevant regulations.
Therefore, when collecting user data, we need to follow clear consent procedures and implement appropriate security measures to ensure data confidentiality and protection. Additionally, we should refrain from unauthorized disclosure or improper use of collected data. By maintaining user trust and appropriately managing personal information, we can enhance the social impact of our project.